
PixelRNN
图像由pixel构成,在随机给了初始的pixel之后,当作输入放到model中去,output是什么样的pixel,那么就在初始pixel之后补上该输出,然后目前有的pixel都又当作输入进入model,直到完成绘图。
描述一个pixel可以采用RGB表示,每一个pixel就是三维的vector,但是按照上面的描述我们的input pixel是可变的,他把上一次的输出当作了输入,因而需要用到RNN。
VAE Variational Auto-encoder
如果把auto-encoder中的NN decoder单独拿出来,通过随机生成一个向量当作该decoder的input code,看能不能输出图像?但是结果不太好。
此时需要VAE,沿用auto-encoder中encoder和decoder两个部分,但是在中间结果中对encoder的输出/decoder的输入做一些变更,训练的目的就是minimize reconstruction error。
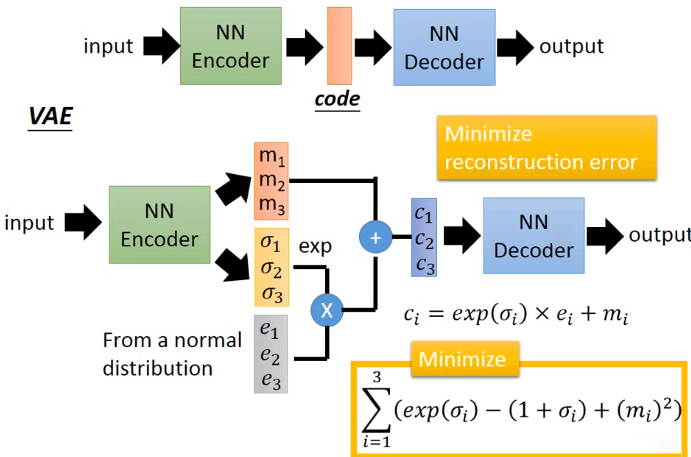
做那些变更?通过引入一个normal distribution和$\sigma$方差来增加noise。增加noise的目的是让稍微变化了之后的code进入decoder之后还能够还原变化之前的code,有容错能力。
如何minimize reconstruction error?其实就是通过这个loss function找对应的$\sigma$的值。本质上这些变更还是在train一个NN。
为什么loss function是这样的形式?可以看到当$\sigma$取0的时候,前面两项直接就是0,让error最小,相当于什么也没有学到,所以需要一个L2 regularization term,让结果不会overfitting。
局限在于只能模仿,不能创造。
VAE是gaussion mixture model distributed representation的版本。
我们从一个normal distribution(这个normal distribution是一大堆gussian distribution的表示)中sample出一个z,这个z接下来会决定某个特定的gaussion distribution的expectation和variance。
如何决定z?相当于z作为input通过了两个function(也就是通过一个NN训练出来),得到了expectation和variance。通过这个特定的高斯分布,就可以获得最终的x的分布。求x的分布就是条件概率分布求解。
GAN Generative Adversarial Network
Generator和Discriminator协同更新。
第一代generator不知道real data是什么样的,根据随机的输入生成一大堆不是很好的东西。
第一代discriminator在看过real data后,判断generator的生成物是0或1,0判断为这个是假的是生成的,1判断为这个是real的。
genrator为了骗过discriminator根据generator的评判结果不停地优化参数,discriminatior也不不停地优化。
Generator
randomly sample a vector — NN generator — image — discriminator — score on the image
以上的流程和一个完整的NN是很类似的,只不过在调整generator的参数的时候要fix住discriminator的参数,且要做到让generator的评判结果越来越靠近1。
Discriminator
辨别器适用于判断生成器的结果是否是真的。生成器会根据辨别器的判断结果去重新调整自己的参数。
整个流程的生成结果是基于discriminator的,问题在于discriminator如果很弱就没有办法达到预期目的。
- 本文标题:深度生成模型
- 本文作者:徐徐
- 创建时间:2020-11-07 08:14:40
- 本文链接:https://machacroissant.github.io/2020/11/07/generative-model/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!