
Bagging
流程
有N笔Training Data,从中做sampling,建立多个有相同数据量的dataset。
用一个复杂的模型对这些dataset做learning,可以得到四个训练好的模型。
最后将这四个模型的结果做Average/Voting。
适用于什么情况
模型复杂,但是bias很小;主要担心overfitting,目的是为了降低variance,将这些用subset训练好(但是只做重采样效果也不一定很好)的子模型做平均/投票。
比如decision tree这样的模型,Random Forest就是决策树做bagging的版本。传统的决策树很容易在训练集上0% error rate。
传统的随机森林是通过之前的重采样的方法做,但是得到的结果是每棵树都差不多(效果并不好)。比较多的是随机的限制一些特征或者问题不能用,这样就能保证就算用同样的dataset,每次产生的决策树也会是不一样的,最后把所有的决策树的结果都集合起来,就会得到随机森林。
如何验证Validate
如果是用Bagging的方法的话,用out-of-bag可以做验证,不需要把label data划分成training set和validation set。
对于一个function1,用dataset1和dataset2训练;对于function4,用dataset2和dataset4训练。function1和function4做bagging的结果可以用dataset3来做测试。对所有的function的组合做out-of-bag测试,最终的error是这些测试结果的平均。
Boosting
适用于什么情况
适用于错误率很高的模型,没有办法fit。
Boosting有一个很强的保证:如果你的机器学习算法能产生错误率小于50%的分类器,这个方法可以保证错误率达到0%。
流程
- 先找一个分类器f1(x)
- 接下来找一个辅助f1(x)的分类器f2(x),f2(x)不能和f1(x)很像,f2(x)要能够弥补f1(x)没办法做的事情
- 之后再找辅助f2(x)分类器的f3(x),一直到最后
注意所有分类器都是按照顺序sequentially得到的。而bagging是没有顺序的,可并行训练。
细节实现
如何使classifers — fk(x)不相同?
要让每个分类器的参数不同,可以让他们在不同的dataset上训练。
为了获得不同的数据集,可以重采样原数据集Resampling,就像bagging做的那样;也可以重新给原数据集中的每一个数据重新分配权重,即Re-weighting。
Adaboost
总的想法就是先训练好一个分类器f1(x),然后再找一组新的training data,让f1(x)在这组data上表现很差(怎么才算表现差?),然后让f2(x)在这组training data上训练。

将分类器f1(x)中的训练数据的权重变更(要怎么变更?)后,我们要找分类器f2(x)在新权重的训练集上error rate等于0.5。

如何确定
已知
变形获得
算法总结

- 多个模型的sequential训练

- 将多个训练好的模型组装,两种方式Uniform Weight/Non-uniform Weight。
正确性验证
要保证最后组装起来的模型
问题转换1
最终的error rate是有上界的,蓝色的函数就是绿色函数的上界。
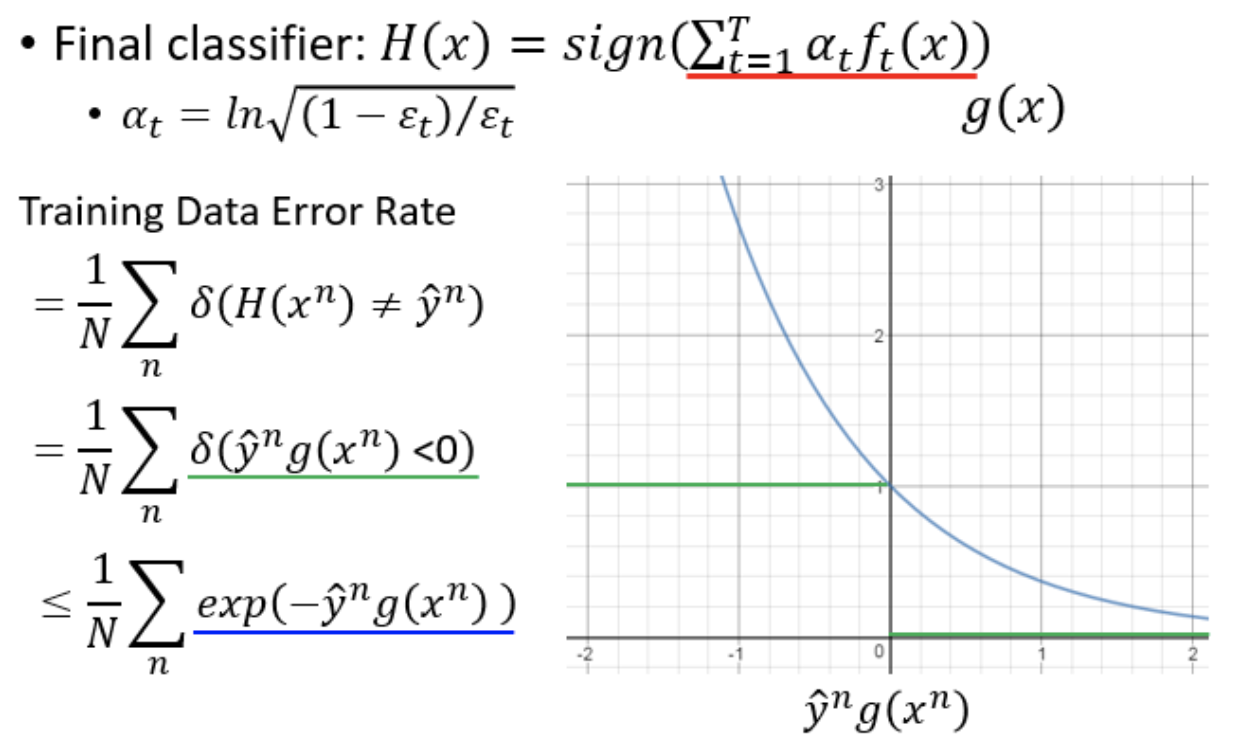
要证明最终的函数
问题转换2
对蓝色部分的上界函数做一些变形。
用$u^n{T+1}

要证明蓝色的上界函数会越来越小就转化为要证明训练数据的权重和会越来越小。
问题转换3
对训练数据的权重和做一些变形。
在用第T+1次训练数据集权重的和$Z{T}

最终经过三次转换证明成功。
Gradient Boosting
Gradient Boosting是Boosting更泛化的一个版本。

给定initial function,在每个timestep更新上一个timestep的function,得到最终的output Function。
从梯度的角度考虑loss function,是上面那个式子,更新就是learning rate和对g(x)微分的结果。
从boosting的角度考虑就是要添一个新的函数。
如果这两个同方向就可以最小化损失函数。要让他们同方向就要让这两个式子同符号,把这两个式子的乘积最大化。

Adaboost中就自动分配了一个最好的
Gradient Boosting中我们可以自己决定学习率,从而更改目标函数。
Stacking
在分类问题中直接对不同结果的模型做Voting并不一定是好的,有的系统比较差。
当然可以采用bagging分配子系统在最终结果中的权重。
提出另一种方法,把子系统的输出结果当作新的特征输入到最终的分类器,这个分类器比较简单。Training Data分成两份,一份用来训练子系统,另一份用来训练最终分类器。
- 本文标题:集成学习
- 本文作者:徐徐
- 创建时间:2020-11-11 10:49:02
- 本文链接:https://machacroissant.github.io/2020/11/11/ensemble/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!