
interact with environment
两种方式
强化学习,机器在和环境互动的过程中,从环境获得reward,学习如何获得更高的reard。
learning by demostration/imitation learning,其中inverse reinforcement learning就是其中一种。
whole idea
Action => Observation/Reward
参数更新要Maximize the expected cumulative reward per episode。
训练难点在于Reward delay(如何知道某个action会在将来某个时间点获得正向Reward?),以及Agent’s actions effect the subsequent data it receives.
policy-based: learning an actor; value-based: learning a critic; actor+critic: A3C
Actor
函数描述
Actor/Policy就是一个function,定义为
神经网络的输入就是oberservation,可以被表示成一个vector或matrix。
神经网络的输出就是action或probability of taking the action(stochastic),可以对应到output layer的一个neuron。
Actor/Policy就是神经网络,也就是一个函数。
函数好坏/Goodness of Actor
An episode is a series of state/action/reward, named as trajectories.
这里的state其实就是前面的observation。
Reward就是这个episode中所有reward分量的和。
对于一个序列${s1, a_1, r_1}
现在要machine玩一个游戏,在一个episode结束之后,才能确定表示它的
最大化/Gradient Ascent
在找最小值的时候用Gradient Descent;在找最大值的时候用Gradient Ascent。
对期望
具体过程
注意到
且
问题转换为求
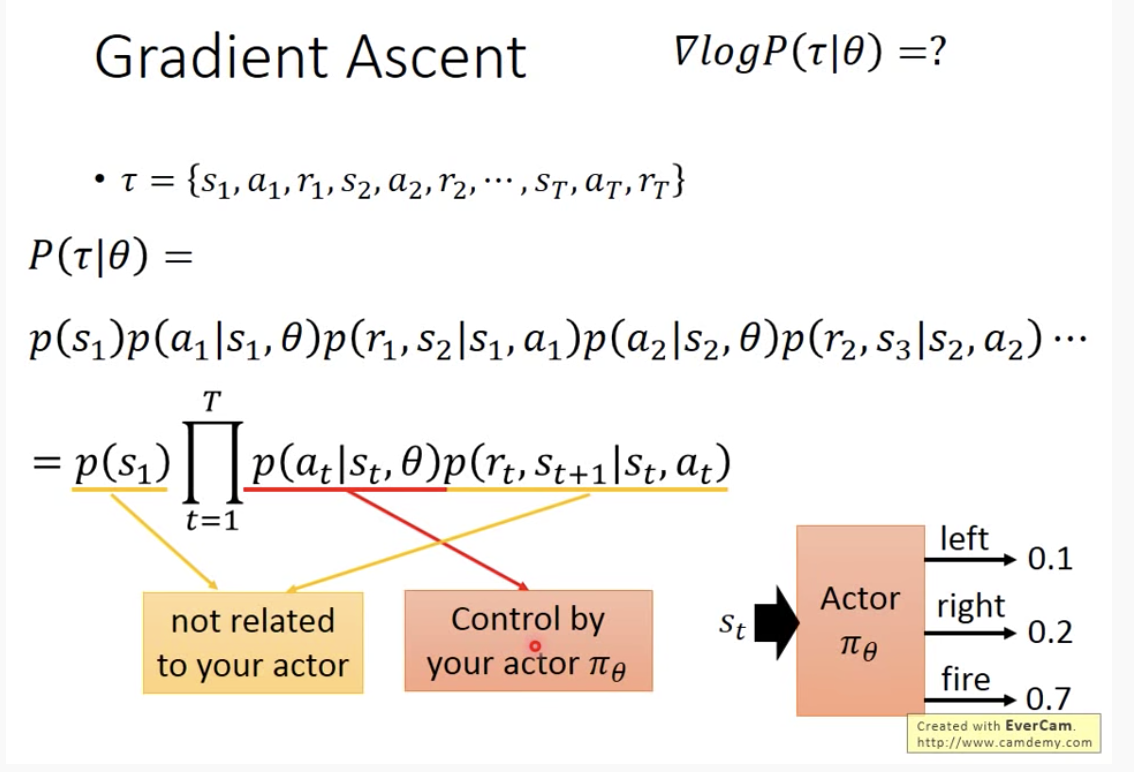
取log之后相乘变相加,做微分之后无关actor的项(黄色部分)都是没有的。
最终更新表达式如下,要注意probability的log做微分之后乘以的是整个episode结束之后的reward,而不是某个action结束之后立马得到的reward。
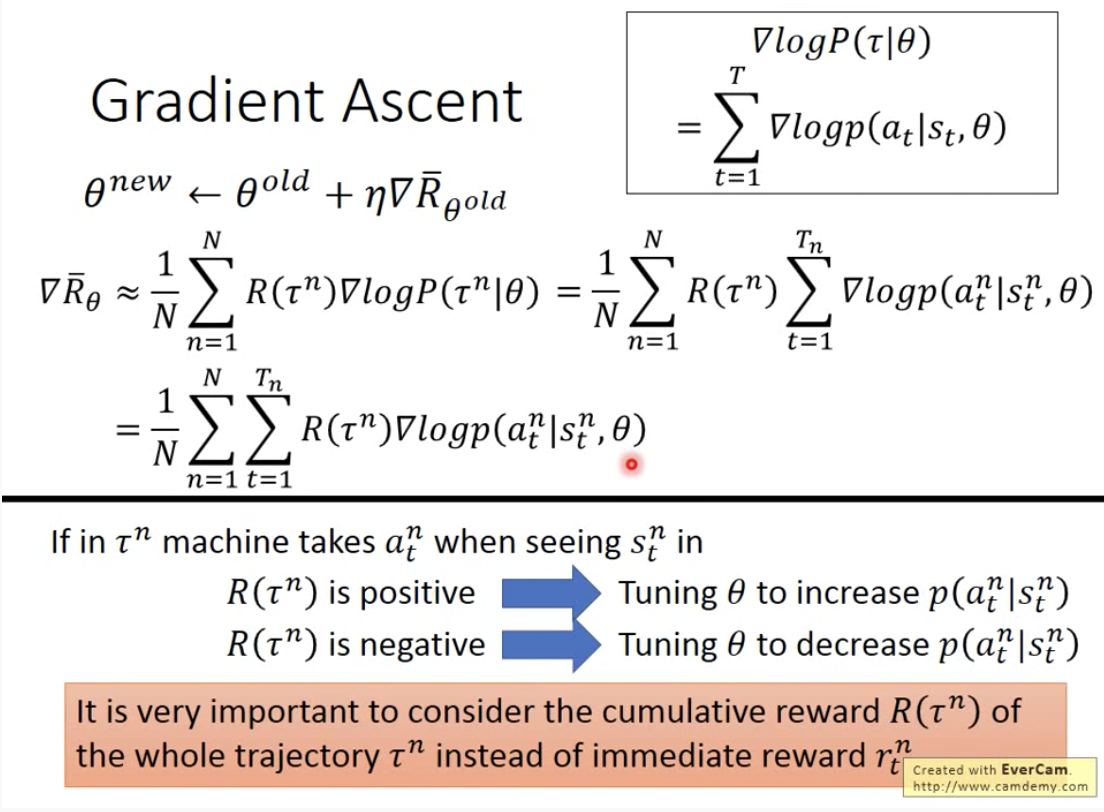
表达式解读
为什么要做log?为什么不用p的微分直接除以p的几率?为什么要除以p的几率?
即使reward并不大出现频率很高的action会被偏好;即使reward很大,出现频率却很低的action对目标的影响很小。
相当于做了一个normalization。
在某一个state我们可以sample到3个action,实际上没sample到的action在做完gradient ascent之后反而会越变越小,其他的action反而无条件的probability增加。
不能让几率无条件增加,所以给
Critic
A critic doesn’t determine the action. Given an actor pi, it evaluates how good the actor is.
State Value Function
When using actor
只要有$\cdots, st, a_t, r_t, s{t+1}, s_{t+1}$这样的state的变化,就能计算并更新参数,不需要像actor一样等到episode完全结束。
State-action value function
When using actor
Q-Learning就是给定一个初始actor pi,让这个pi去和environment互动,用Q function找出一个表现比上一次actor pi更好的actor pi’ 。
Actor+Critic
A3C = Asynchronous Advantage Actor Critic
Inverse Reinforcement Learning
只有action和environment,没有reward function,也就是规则不明确。目标是随着reward function的不断更新,让teache由弱变强,actor跟着teacher一起变强,但总是弱于teacher。
- 本文标题:强化学习
- 本文作者:徐徐
- 创建时间:2020-11-11 15:55:40
- 本文链接:https://machacroissant.github.io/2020/11/11/reinforcement-learning/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!