
GAN基础算法
Initialize
for Generator and for Discriminator In each training iteration:
Learning D Repeat K times
Sample m examples
from database Sample m noise examples
from a distribution(Uniform Distribution or Guassion Distribution)
这些example用多少维度的vector来表示是需要自己调的。
Obataining generated dara
, Update discriminator parameters
to maximize 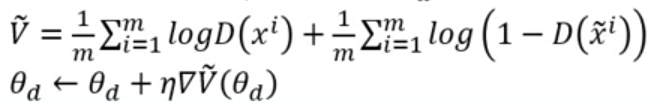
利用gradient ascent求最大值,本质上和gradient descent一样,只不过function符号正负或者update的时候方向和梯度同向还是反向。
这里用到的function并不是表现最好的,只是最早提出GAN的研究者当时采用的算法。
解读第一项就是把从database中sample出来的real image vector经过Dsicriminator之后评分要越高越好。
解读第二项就是把从某个分布随机生成的vector经过discriminator之后评分要越低越好。
算出两个分布之间的JS Divergence,本质上就是一个binary classifier,can only find lower bound of
。
Learning G Only Once
Sample another m noise samples
from a distribution Update generator parameters
to maximize 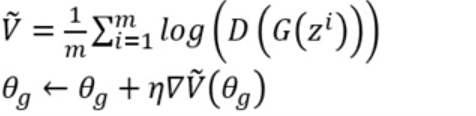
最里层是random noise的vector,外面套了一个Generator就变成了一个image,利用Discriminator去评判这个Generator是否做得够好,希望评分越高越好。
GAN as structured Learning
结构化学习特征
机器学习就是:input — function — output。
当output不再是一个简单的scalar/class(one-hot vector),而要求是sequence(MachineTranslation/Vhat-bot/SpeechRecognition)/tree/graph/matrix(ImageToImage/TextToImage),那么就是结构化学习。
Structured learning’s output is composed of components with dependency.
结构化学习可以看作极端的one-shot/zero-shot learning,机器在学习如何输出在训练时完全没有见到过的东西。
GAN与结构化学习
GAN其实就是结构化学习的一种解决方案。
传统的结构化学习方式有两种。一是Bootom-Up — Learn to generate the object at the component level,一个一个组件单独产生问题是没有大局观念;二是Top-Down — Evaluating the whole object, and find the best one,问题是很难做generation.
以上两种方法结合在一起,bottom-up对应generator,top-down对应discriminator就是GAN。
Generator详解
目标:vectors — NN Generator — image。
要让Generator理解每一层output的component之间的关系,即pixel to pixel relationship,要让网络够深。
NN Generator & Auto-Decoder
在supervised learning中,都给一对vectors/image,但是如何产生这么一对vectors/image,要求我们input vectors和output的特征有某些关系。
由此联想到image — NN Encoder — low-dimension code,但是Encoder不能自己训练,必须要和coder — NN Decoder — image一起训练。可以看出Decoder其实就是Generator。
Auto-Encoder & VAE
但是用decoder做的generator再遇到自己没有遇到的coder的时候产生的结果不可控,就算是vector a和vector b的线性组合通过decoder这个非线性系统之后产生的结果也是不可控的。
如何解决这个问题?采用VAE — Variational Auto Encoder,给encoder的输出做一个偏移,让Auto-Encoder的输出更稳定一点。
困难点
Auto-Encoder没有办法考虑每一层input的每个component之间的关系,即pixel-to-pixel relationship,对应的就是structure learning中boottom-up approach的问题,没有全局观念。
Discriminator详解
Discriminator = Evaluation function = Potential Function = Energy Function
Discriminator更容易去检查pixel-to-pixel relationship,因为它对应的就是structure learning中的top-down approach的优势。
训练方法
real image就是positive example,但是如何产生比较好的十分接近real image的negative example,让discriminator的评分更严格?
采用iterative training。让discriminator的评分从松散到严格。
第一个周期,由初始discriminator parameter决定了discirminator,该discriminator学习给real image distribution的区域高分,给generated image distribution的区域低分。也就是找到了第一个周期的Discriminator。
第2-n的周期,先用第一个/前一个周期的Discriminator产生negative example(如何找,要解一个argmax problem,要做一些假设),重新学习real image distribution/positive example distribution的区域高分,给generated image distribution/generated image distribution的区域低分。
直到discriminator自己产生的neagtive example distribution和实际的真是的positive example distribution重合,discriminator才会停止迭代。
困难点
如何让前一个周期的Discriminator产生negative example?如何找,要解一个argmax problem,要做一些假设,因此效果多少有些差。
把Generator和Discriminator联合起来考虑,用generator来解argmax problem,解决了discriminator的痛点;用discriminator去给generator一个global view。
Advantage

Conditional GAN
WHY CGAN
可操控输出结果。
例如Text-to-Image,可以当成Traditional supervised learning来做。input data对应NN output要和input data label尽可能相近。
问题在于input data/text和input data label/image很有可能是一对多的关系,从而导致模型产生的结果是多张input data label的平均,也就是多张image的平均,所以会特别模糊。
同样Image-to-Image的问题,同样一张几何图形要转换成对应的房子,很有可能一张几何图形可以对应到多个房子。
HOW CGAN
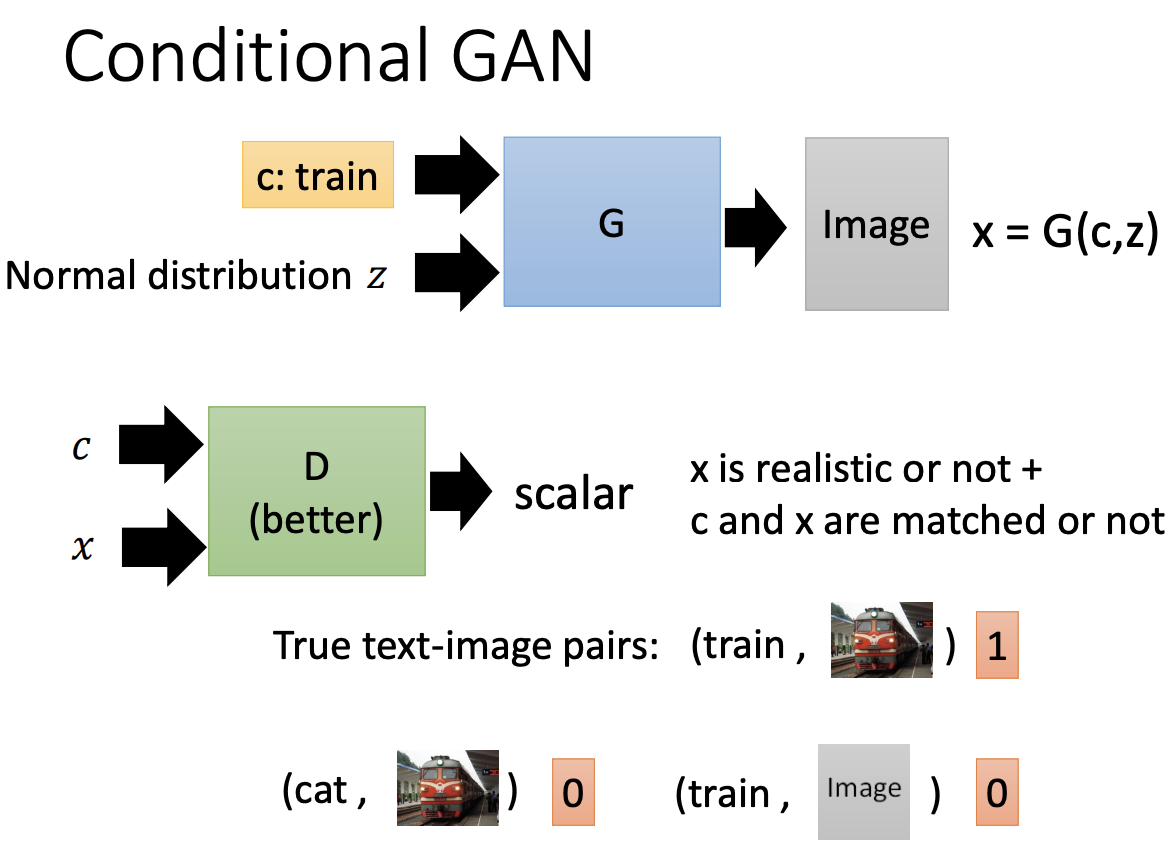
generator的input是condtion和从normal distribution中sample出得z,output是image。
discriminator的input是condition和generator的output image,要求判断output image真假的同时,还要判断这个image的内容和condition是否匹配,output是判断real pair or fake pair的scalar。
为什么discriminator需要也有condition?
假如没有condition作为输入,generator为了骗过discriminator,只要产生real image就行了,根本不用管input condition。
TIPS CGAN
Stack GAN
Patch GAN
Unsupervised Conditional Generation
Transfer an object from one domain to another without paired data(e.g. style transfer)
Direct Transform
Domain X — G{X->Y} — Domain Y
要求1
因为没有Domain X 和 Domain Y之间的link,需要用discriminator协助,让generator产生像是Y Domain的图像。
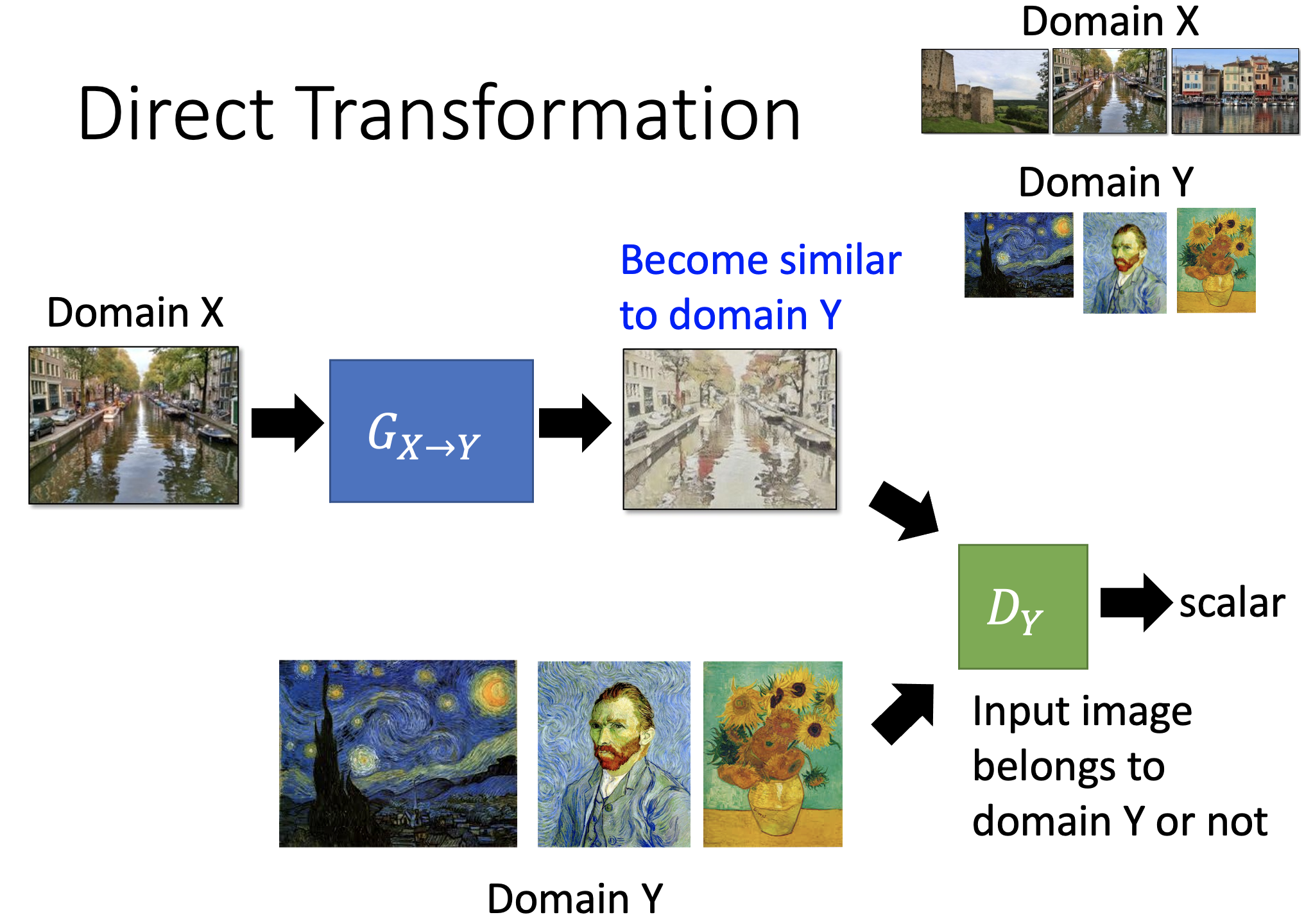
要求2
问题是如果generator直接产生和Domain X没有关系怎么办?我们必须要求generator的输入和输出必须配对。
可以直接无视这个问题,当generator较简单shallow的时候,该generator倾向于不去更改input,那么就不需要做额外的constraint。
或者使用一个pre-trained Encoder Network对generator的输入输出的embedding output越相近越好。
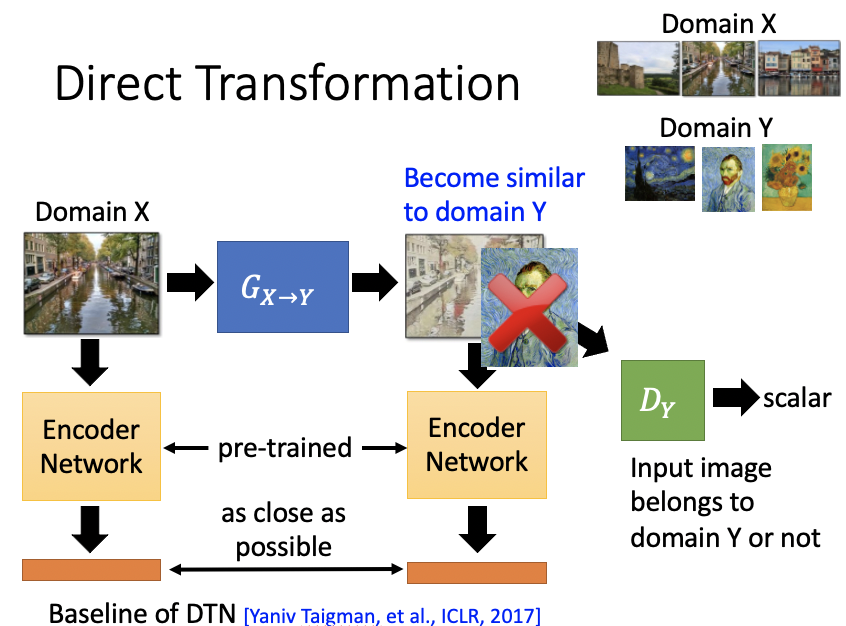
使用CycleGAN。
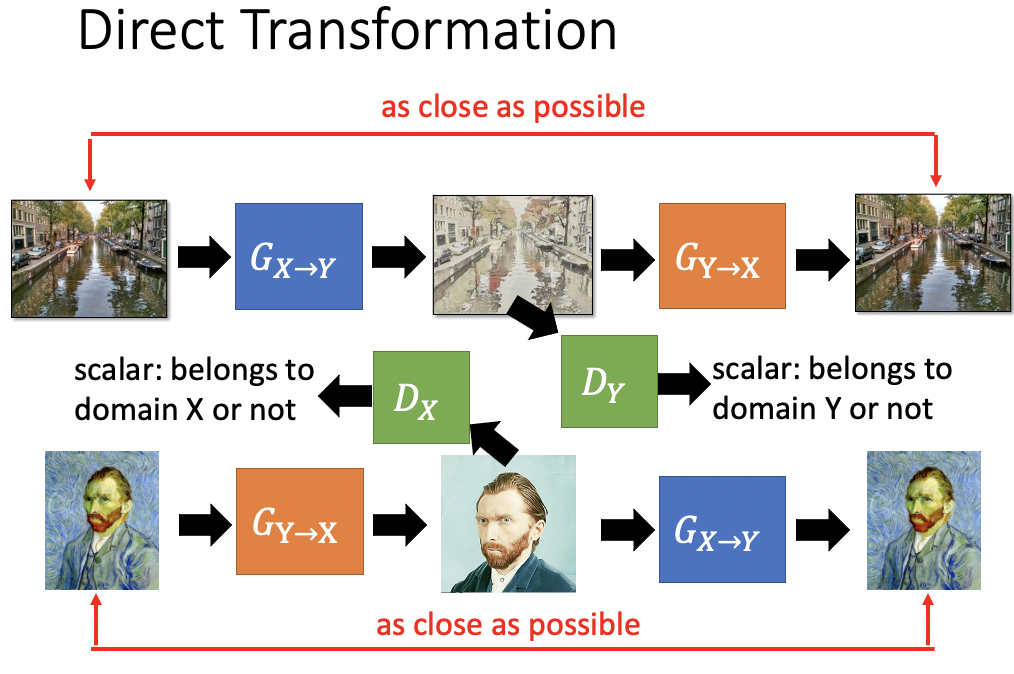
Domain X — G{X->Y} — Domain Y — G{Y -> X} — Domain X,要让经过了两次generator转换前后的Domain X越相近越好,这就是Domain Consistency。
同样可以做双向的CycleGAN。
StarGAN
Projection to Common Space
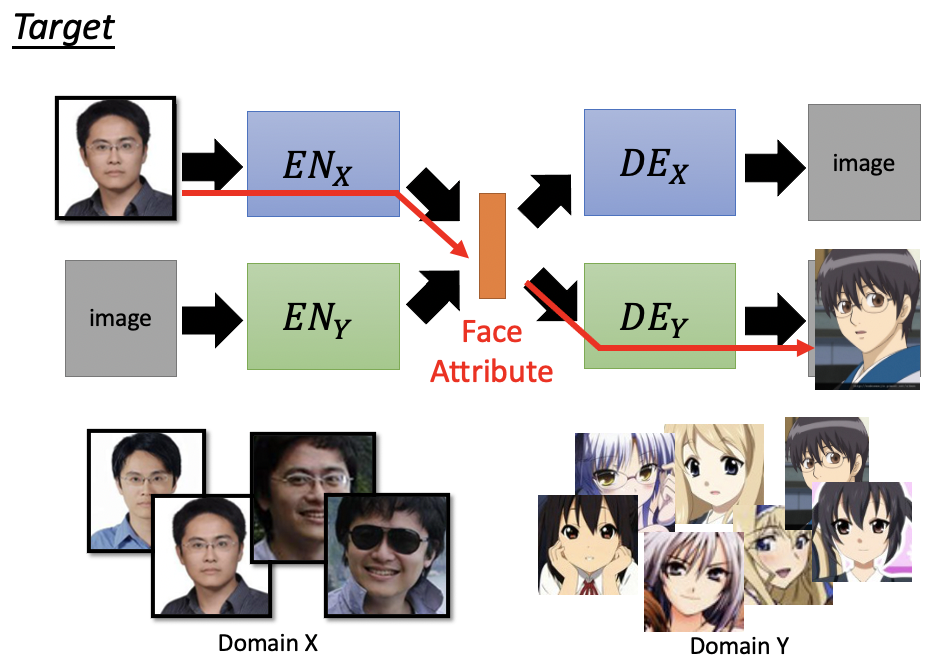
Domain X — Encoder of domain X —Common Attribute at latent space— Decoder of domain Y — Domian Y
Target
Training
基本方法
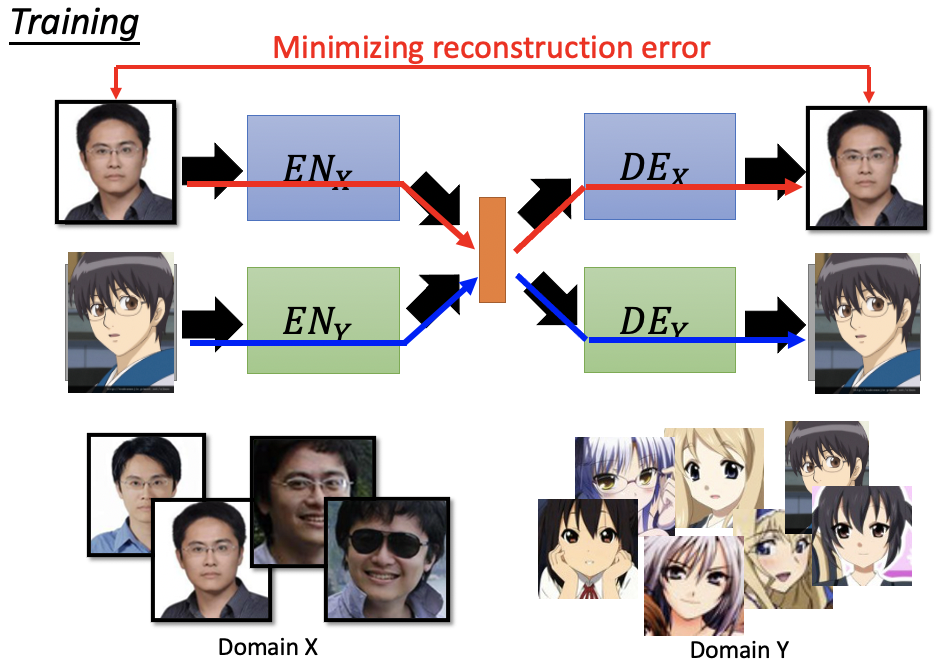
训练Encoder和Decoder就是要Minimizing Reconstruction Error,可以在Decoder的output之后接一个Discriminator of X domain/ Y domain,让Decoder的output不那么模糊。
EncoderX — DecoderX — DiscriminatorX = VAE GAN1
EncoderY — DecoderY — DiscriminatorY = VAE GAN2
存在问题
问题是红色的training和蓝色的training是两个没有交集的训练路径,完全独立的,训练完之后你发现images with the same attribute may not project to the same position in the latent space。
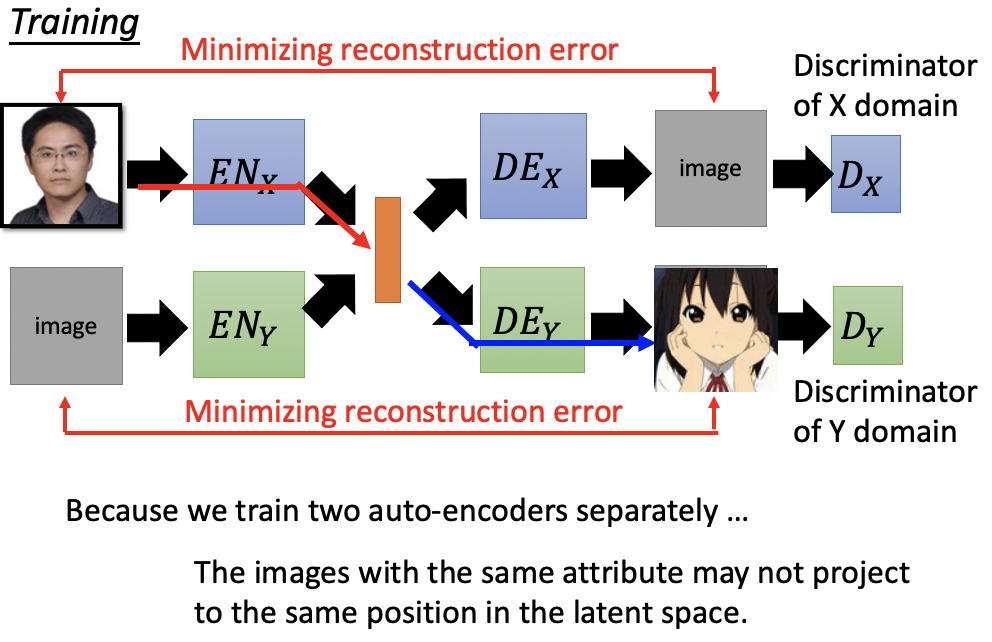
解决办法1
sharing the parameters of encoders and decoders. Encoder共享最后几层的参数,Decoder共享前面几层的参数。
解决办法2
给latent space加一个Domain Discriminator去判断这个code vector是来自EncoderX还是EncoderY。

解决办法3
Cycle Consistency,类似于CycleGAN,算Image和Image之间的consistency。
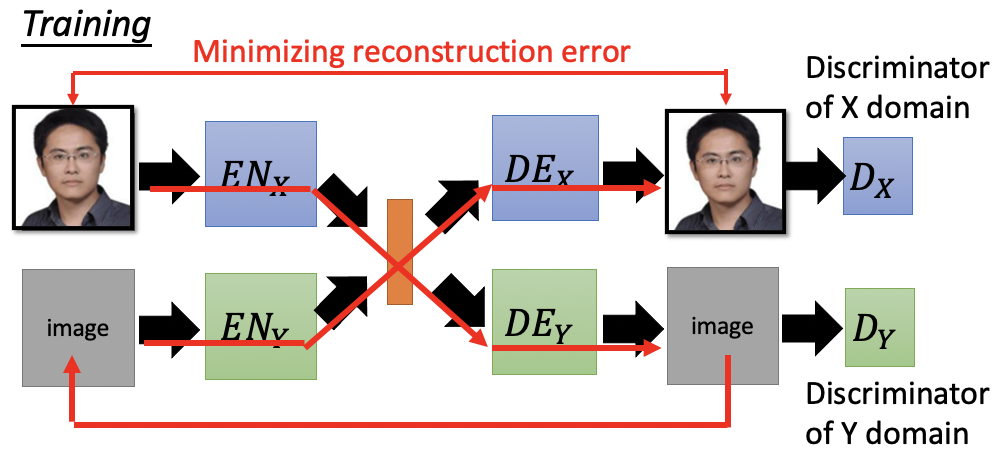
解决办法4
Semantic Consistency考虑在latent space上的consistency。
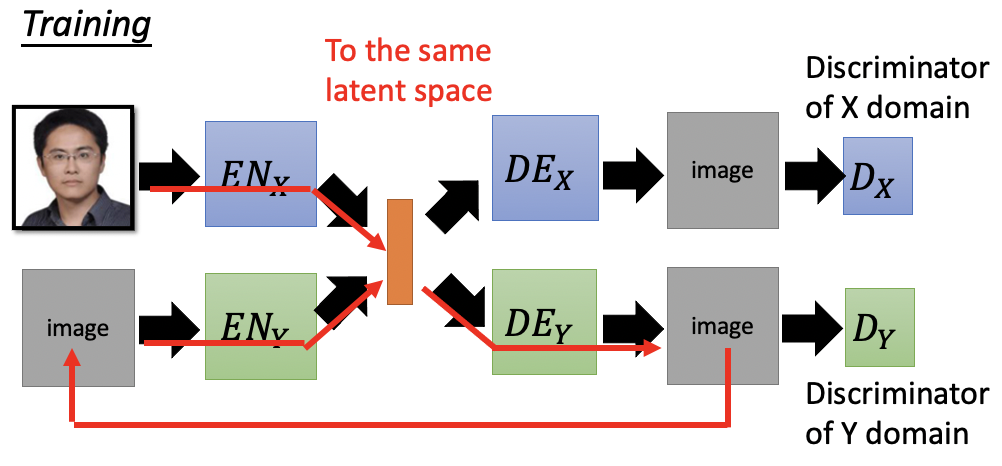
- 本文标题:GAN Introduction
- 本文作者:徐徐
- 创建时间:2020-11-12 11:16:01
- 本文链接:https://machacroissant.github.io/2020/11/12/GAN-tutorial/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!